Deepseek V3/R1 intra/inter node all-to-all communication
Recently, DeepSeek V3 made headlines by being able to train 14.8 trilion tokens using only 2.788 million H800 GPU hours. This was estimated to be several times more efficient than approaches that did not incorporate DeepSeek’s LLM and training infrastructure designs.
In the initial 2024-12-26 announcement for DeepSeek-V3, and subsequently the publishing of the inference repo, one part that remained missing stood out to me; which is on how the cross GPU communication kernels are implemeneted.
3.2.2. Efficient Implementation of Cross-Node All-to-All Communication
… In detail, we employ the warp specialization technique (Bauer et al., 2014) and partition 20 SMs into 10 communication channels. During the dispatching process, (1) IB sending, (2) IB-to-NVLink forwarding, and (3) NVLink receiving are handled by respective warps. The number of warps allocated to each communication task is dynamically adjusted according to the actual workload across all SMs. Similarly, during the combining process, (1) NVLink sending, (2) NVLink-to-IB forwarding and accumulation, and (3) IB receiving and accumulation are also handled by dynamically adjusted warps. In addition, both dispatching and combining kernels overlap with the computation stream, so we also consider their impact on other SM computation kernels. Specifically, we employ customized PTX (Parallel Thread Execution) instructions and auto-tune the communication chunk size, which significantly reduces the use of the L2 cache and the interference to other SMs.
From the quote above in their paper, I’m also curious about what customized PTX instructions are used. Given that these are missing in their repo, I suspected it was a secret sauce that they didn’t intend to share.
Fortunately, I was proven wrong as the DeepSeek team published the DeepEP repo on 2025-02-26.
Thus my post below will attempt to analyze the key designs in the communication kernel.
Table of Contents
- The Problem: Scalable MoE in LLMs
- Key Design Choices for Efficient Communication
- Communication Kernel Implementation Details
- Appendix
The Problem: Scalable MoE in LLMs
Modern large language models (LLMs) started introducing a layer called “Mixture of Experts” (MoE) in their Transformer blocks to scale parameter count without linearly increasing compute. This is typically done through top-k (often k=2) “expert routing”, where each token is dispatched to two specialized feed-forward networks (experts) out of a large pool.
A naive GPU cluster implementation would be to place each expert on a separate device and have the router dispatch to the selected experts during inference. But this would have all the non-active experts idle on the expensive GPUs.
GShard, 2021 introduced the concept of sharding these feed-forward (FF) experts across multiple devices, so that each device:
- Processes a partition of tokens (a token “group”), computing gating scores (often with softmax) to decide which experts these tokens should go to.
- Dispatches embeddings to remote devices that host the relevant experts.
- Combines the outputs from those experts, which are sent back from other devices, before proceeding to the next layer in the Transformer.
This diagram from GShard paper illustrates how the cross device communication happen
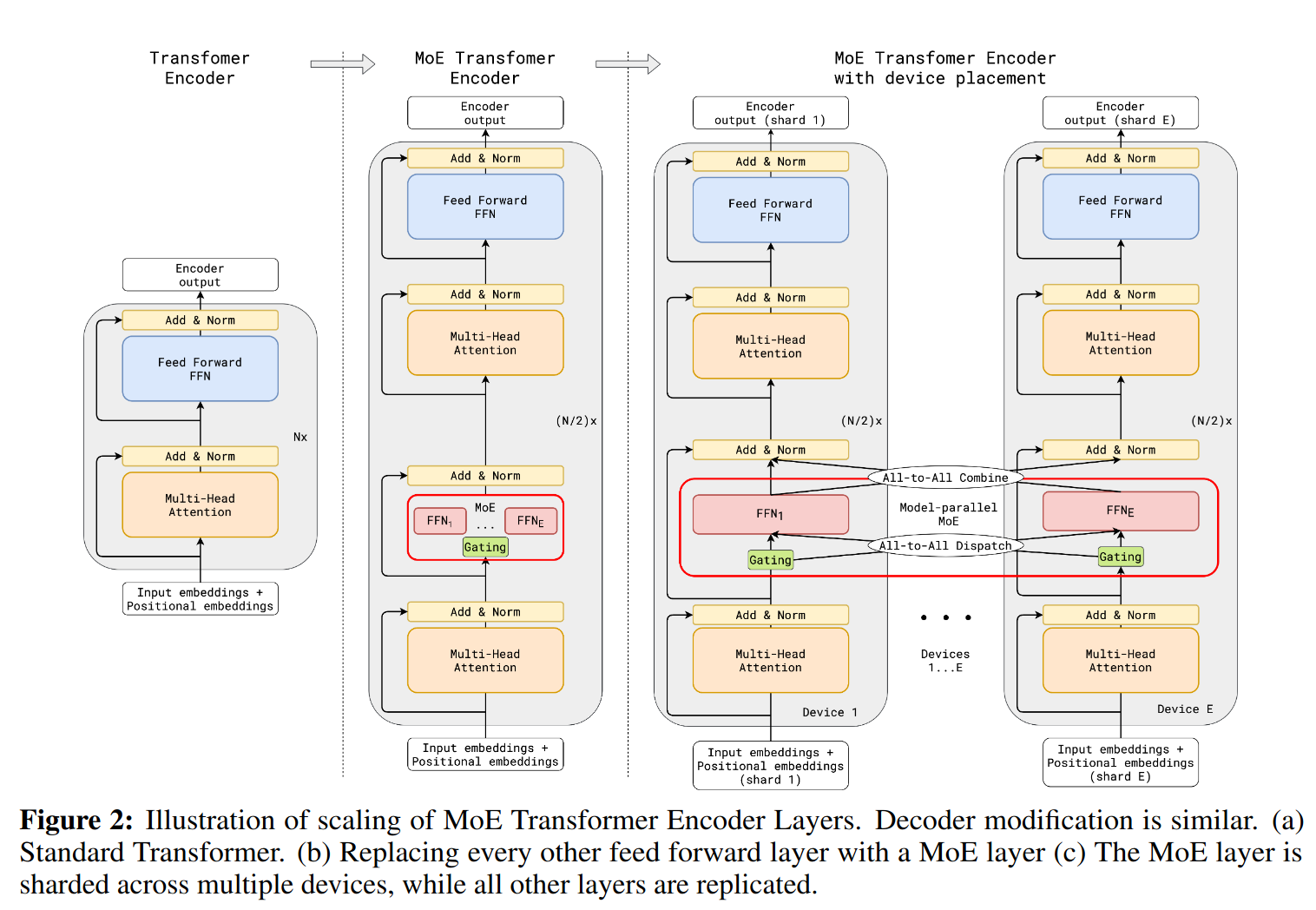
- It is worth clarifying that the transformer block in each shard is processing the full token embedding, thus the attention itself are complete and do not depend on other shards. It is only the [tokens, channels] going into each shard’s FF need to be assembled from tokens coming from remote devices. I think of each shard’s group tokens as a mini-batch in itself.
The challenge: all-to-all communication
Each device must send chunks of embeddings to potentially every other device (intra-node via NVLink, inter-node via InfiniBand RDMA). If done naively, this quickly becomes a communication bottleneck. DeepSeek’s DeepEP addresses this with specialized CUDA kernels that optimize dispatch and combine steps for both inter- and intra-node traffic, while also seamlessly overlapping communication with local compute to hide each other’s latency.
Key Design Choices for Efficient Communication
DeepEP’s performance gains revolve around carefully orchestrating the overlap of communication and compute while optimizing low-level CUDA operations for the specific MoE data patterns.
-
Dual-Stream execution
Each device runs two CUDA streams in parallel:
- Compute Stream: Handles attention, softmax, feed-forward, and layer normalization for the local tokens
- Communication Stream: Handles all the dispatch/combine operations for MoE.
By running both streams concurrently, together with careful scheduling, DeepSeek claims to
This overlap also ensures that, as the model further scales up, as long as we maintain a constant computation-to-communication ratio, we can still employ fine-grained experts across nodes while achieving a near-zero all-to-all communication overhead
-
Hand-Rolled CUDA Extensions
DeepEP provides a custom deep_ep.cpp CUDA extension with an API that combines:
- Intra-node NVLink communication kernel for MoE dispatch/combine
- Inter-node InfiniBand RDMA
This allows fine-grained control over reading/writing GPU memory for dispatch and combine. By tailoring these kernels to MoE’s all-to-all pattern, they avoid generic overhead and can exploit hardware features like warp-specialized loops, ring buffers, and pinned memory.
-
Using out-of-doc PTX instruction to minimize interference between the Communication and Computation stream
To reduce L1 cache thrashing, DeepEP uses specialized (and whose behavior IS NOT officially guaranteed) PTX such as
ld.global.nc.L1::no_allocate.L2::256Bandst.global.L1::no_allocate. Whose aim being to load/store from/to global device memory without going through L1-cache. -
Warp Specialization
In the cusotm communication kernels, each warp is dedicated to a single rank. This design ensures minimal control-flow divergence, since each warp can follow its own uniform dispatch logic based on the rank’s data. By isolating rank logics to warps (rather than threads), the warp scheduler do not need to process separate thread groups within the warp for each branch sequentially.
-
Topology-Aware Routing
For inter-node transfers, DeepEP tries to send data directly to the matching device on the remote node (with the same local index). Once data arrives, it is instantaneously forwarded (via communication kernel code) to other devices via NVLink if necessary. This approach exploits direct IB links for node-to-node traffic while fully leveraging NVLink’s fast in-node bandwidth. This allows both NVLink and IB to operate simultaneously.
Communication Kernel Implementation Details
DeepEP’s all-to-all logic is split across four main CUDA plus (plus variatns for low-latency mode):
- Intra-Node dispatch
- Intra-Node combine
- Inter-Node dispatch
- Inter-Node combine
These kernels share a similar structure but differ in how they access GPU memory (NVLink vs RDMA) and handle ring buffers.
Resource Utilization
- Each intra-node kernel can occupy up to 20 out of 132 SMs on the H800 GPUs DeepSeek use. (Exact numbers differ for inter-node kernels).
- SM usage is partitioned so that half are senders and half are receivers, preventing resource contention.
Warp-level Rank Handling
- Each warp is dedicated to a single rank. Kernel code are structured such that branching happens in threads that falls in the same warp.
Communication Steps
- Notify Dispatch
- A kernel uses 1 SM to broadcasts the number of tokens to be send, and “# of ranks” SMs to receive the information in the
notify_dispatchstep. - Each warp receives that info and calculates how much bytes it needs to expect for incoming data.
- A kernel uses 1 SM to broadcasts the number of tokens to be send, and “# of ranks” SMs to receive the information in the
- Dispatch
- The dispatch kernel then transfers
[token, channel embeddings]from the sender’s global memory directly into the ring buffer on the remote device. This is done either via NVLink (for intra-node) or RDMA (for inter-node). The sending kernel increments the remote device’s ring buffer tail pointer as data is written. Conversely, the receiving kernel increments the sender’s device ring buffer head pointer as data is received.
- The dispatch kernel then transfers
- Combine
- Similar to dispatch, the combine kernel has sender and receiver warps. And utilizes ring buffer pointer to notify each other of data transmission.
** It is interesting to note that all communication are point-to-point instead of utilizing library like NCCL to perform gather/scatter. I suppose this is a natural outcome of having each warp be responsible for a src/dst rank communication.
Finally, to visualize the SM allocation for communication, here’s a breakdown of DeepEP’s config on intra-node communication kernels that uses 8 devices.
| method | SM | thread |
|---|---|---|
| notify dispatch | 1 + 8 (1 send, 8 receive) | 128 |
| dispatch | 20 (even send, odd receive) | 128 |
| combine | 20 (even send, odd receive) | 768 |
Appendix: Links of key implementation design to github repo
Here are some links to sections of the code that is responsible for the key communication designs
| idea | description | location |
|---|---|---|
| dual stream communication | toggling communication/compute stream | DeepEP/csrc/deep_ep.cpp |
| out-of-doc PTX load/store | by-pass L1 cache load/store | DeepEP/csrc/kernels/utils.cuh |
| warp specialization | kernel do branching in same warp | DeepEP/csrc/kernels/intranode.cu |
| topology-aware routing | forward either on IB or NVLink | DeepEP/deep_ep/buffer.py |